For a while now, I track my humble little website with Snowplow Analytics on the Google Cloud platform. Nothing fancy, just a basic setup.
But.. having a really powerful limitless platform like Snowplow running and collecting only the basics is a bit like using your Ferrari to get groceries. In this post, I’ll show you how to take your Snowplow install a small step further.

If you run on AWS, please follow this tutorial on the Snowplow forum. If not: read on.
Introductory guide to creating your own self-describing events and contexts (Google Cloud Edition)
In this post I’ll follow the following steps:
- Think of what you want to measure (and how)
- Create the self-describing json schema (and lint it)
- Tell snowplow where to find the schema:
- upload to the iglu server file structure
- configure the iglu client
- Prepare the database – add the column to BigQuery
- Send measurements: Add it to the javascript tracker
- Use the data – Query the results
It looks like a long list (and it is), and it’ll probably take you a while the first time, but the groundwork you’ll have to do only once.
Ready? Then log into your Google Cloud Console, and off we go!
What do you want to measure?
You probably have your own itch to scratch, or else you weren’t reading this. You want to measure something extra via Snowplow. You have to consider the following:
- is it a “stand-alone” event, like a registration on your site? Then you’ll probably want to configure a Snowplow unstructured event.
- Is it some extra information for an existing measurement? Then you’ll need a context to add to an existing event.
In this example, I’m going to add some WordPress page data information to the existing page tag. This is provided by the Google Tag Manager WordPress plugin in the dataLayer of the page. I’ll pick 3 elements here.
- visitorLoginState – is the page viewed by a logged-in visitor?
- postCountOnPage – how many posts are on the page?
- pagePostType – what kind of page is it?
For Google Analytics users: these 3 fields you can probably put in some hit-scoped custom dimension.
For now: There’s no limit in the number of data-fields to add per context.
Create the self-describing json (and lint it)
In this step, we’ll describe what we want to measure in a structured json file. And when I say structured, I mean it. Snowplow is really strict.
By design. In the end, the data is going to be inserted into a database, and databases are really picky, too. You cannot insert a string into a numeric column: the world would end if you could do that.
Let’s show you the schema and disect it later:
{
"$schema": "http://iglucentral.com/schemas/com.snowplowanalytics.self-desc/schema/jsonschema/1-0-0#",
"description": "Schema for a page view context",
"self": {
"vendor": "com.stuifbergen",
"name": "gtm4wp_page_context",
"format": "jsonschema",
"version": "1-0-0"
},
"type": "object",
"properties": {
"visitorLoginState": {
"type": ["string", "null"],
"maxLength": 50,
"description": "is visitor logged in"
},
"postCountOnPage": {
"type": ["integer", "null"],
"minimum": 0,
"maximum": 1000,
"description": "how many posts on the page"
},
"pagePostType": {
"type": ["string", "null"],
"maxLength": 50,
"description": "What is the post type"
}
},
"minProperties": 1,
"additionalProperties": true
}
Things to note:
- Vendor I use is
com.stuifbergen– that is the notation to describe vendors. A reverse domain-like notation. - Name of the schema is
gtm4wp_page_context. Sorry for the stupid name, it stands for Google Tag Manager for WordPress. - Properties that are in the object are the ones I want to track, plus how those properties should be formed
- String or a Number, with maximum length / range
- is a null value allowed
- a description (instant documentation!)
Finally, the additionalProperties here is set to true. This makes the tagging valid, even if there’s other stuff sent to the collector. Not recommended if you’re really, really strict. But hey, it’s my blog. Only I care :)
Check the schema!
Before continuing, check that your schema is valid. Use the igluctl program with the lint option to do this.
./igluctl lint yourSchema.json
Continue if there are no errors.
Tell snowplow where to find the schema
Ok, so you have the schema on your local machine. Now, you want to put the schema some place where it’s readable by your Snowplow system, in this case the iglu client.
The ETL process uses an iglu client to resolve the schema path. The schema path looks like this:

Upload the iglu server file structure
There’s several methods. In this tutorial, I’ll create a static, public repository which is hosted in a public Google storage bucket. Simple as that.
Here’s where I want the schema to be found:
https://storage.googleapis.com/datadatadata.nl/prod/schemas/com.stuifbergen/gtm4wp_page_context/jsonschema/1-0-0
To do this, create a public bucket, and make the following path structure:

Then, upload the schema file and name it 1-0-0.
Via the command line, gsutilwill create the structure automatically.
gsutil cp yourSchemaFile.json gs://datadatadata.nl/prod/schemas/com.stuifbergen/gtm4wp_page_context/jsonschema/1-0-0
To make the bucket publicly readable, add the allUsersuser with view rights:

Configure the iglu client
In order to let the iglue client find your schema, add a lookup-location chunck to your iglu_resolver.json file (see last block below).
{
"schema": "iglu:com.snowplowanalytics.iglu/resolver-config/jsonschema/1-0-1",
"data": {
"cacheSize": 500,
"repositories": [
{
"name": "Iglu Central",
"priority": 0,
"vendorPrefixes": [ "com.snowplowanalytics"],
"connection": {
"http": {
"uri": "http://iglucentral.com"
}
}
},
{
"name": "Iglu Central - GCP Mirror",
"priority": 1,
"vendorPrefixes": [ "com.snowplowanalytics"],
"connection": {
"http": {
"uri": "http://mirror01.iglucentral.com"
}
}
},
{
"name": "Stuifbergen Static Repo (HTTP)",
"priority": 2,
"vendorPrefixes": [ "com.stuifbergen" ],
"connection": {
"http": {
"uri": "http://storage.googleapis.com/datadatadata.nl/prod"
}
}
}
]
}
}
The iglu client is used by your ETL process. It validates the collected fields using this schema.
Prepare the database – add the column to BigQuery
Ok, if all is well, you have a hosted schema, and a working iglu configuration resolver file now. Almost there.. still a couple of more steps to go.
In order for the measurements to be inserted correctly into the database, you need to create add a nested column.
Luckily, this is made really easy by the snowplow bigquery mutator executable. This is located on your ETL machine (or on your local machine – make sure to set the permissions).
The add-column flag will add the column.
./snowplow-bigquery-mutator-0.1.0/bin/snowplow-bigquery-mutator add-column \ --schema iglu:com.stuifbergen/gtm4wp_page_context/jsonschema/1-0-0 \ --shred-property CONTEXTS \ --config $(cat bigquery_config.json | base64 -w 0) \ --resolver $(cat iglu_resolver.json | base64 -w 0)
If this command worked succesfully, you should immediately have the column available in your database:

Restart your ETL process
Now is a good time to (re)start your ETL process. (snowplow-bigquery-loader) Make sure it uses the updated iglu resolver configuration file.
Send measurements: Add it to the javascript tracker
Ok.. all the Snowplow configuration work is done. Time to add the measurements to your tracker.
In my case, I add webPage: true, to enable page contexts to be sent.
Also, I add the context to the trackPageView call.
window.snowplow('newTracker', 'mycljcoll', 'tracker.datadatadata.nl', {
appId: 'stuifbergen',
cookieDomain: 'stuifbergen.com',
platform: 'web',
contexts: {
webPage: true,
performanceTiming: true
}
});
window.snowplow('trackPageView', document.title,
[{
schema: 'iglu:com.stuifbergen/gtm4wp_page_context/jsonschema/1-0-0',
data: {
visitorLoginState: {{DL - visitorLoginState}},
postCountOnPage: Number({{DL - postCountOnPage}}),
pagePostType: {{DL - pagePostType}}
}
}]
);
As you can see, I add a context, and tell the tracker that this is a gtm4wp_page_context/jsonschema/1-0-0 schema context.
Then, as data, I send the 3 fields I want to track. The {{ and }} are not javascript, it’s Google Tag Manager variables.
When this is in place: deploy your tagging configuration and start tracking!
Use the data – Query the results
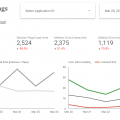
Finally.. it’s time to use the data.. if you have followed all the steps, data is streaming into your BigQuery instance.
Here’s a sample query:
select page_urlpath, page_post_type, visitor_login_state, avg(post_count_on_page) as avg_postcount, count(*) as n from `PROJECTNAME.DATASETNAME.pageviews`, unnest( contexts_com_stuifbergen_gtm4wp_page_context_1_0_0 ) group by 1,2,3
And the results should look something like this:

If so: congratulations! You are now a Snowplow custom schema creator, and are ready to truly up your datamodeling game.
Now that you’ve done this..
You can add unlimited custom measurements to your Snowplow platform.
Do you have built-in data-structures in your website or app? Just pass them to snowplow as-is. No need to squeeze them into a data-model that is built-in the analytics tool you happen to use. Feel free to track data how you want.
Questions, comments?
Let me know in the comments, or shoot me a tweet @zjuul– thanks!

This is an awesome guide Jules! The BigQuery Mutator has a “listener” mode (https://github.com/snowplow-incubator/snowplow-bigquery-loader/wiki/Setup-guide#listen) that means when it sees a new event or context, it automatically creates the additional columns required. This should mean that as a user, you can simply add new schemas to your registry, and the tech automatically handles the rest.
Have you had an opportunity to give that a try?
Thanks Yali!
Haven’t tried the listener mode you mentioned. Sounds really cool, one less step, I will definitely try it.
Hi Yali,
It seems like the link you sent is not valid anymore. do u know why?
Thank you JULES! really helpful article!!!!